简介
1 | by:https://xj.edisec.net/challenges/24 |
ssh日志存在于/var/log/auth.log
题目分析/var/log/auth.log.1
1.有多少IP在爆破主机ssh的root帐号,如果有多个使用”,”分割
原本想查看ssh登陆日志后过滤包含root的内容
但是grep "root"报错
搜报错信息 我们可以使用 grep -a "root"
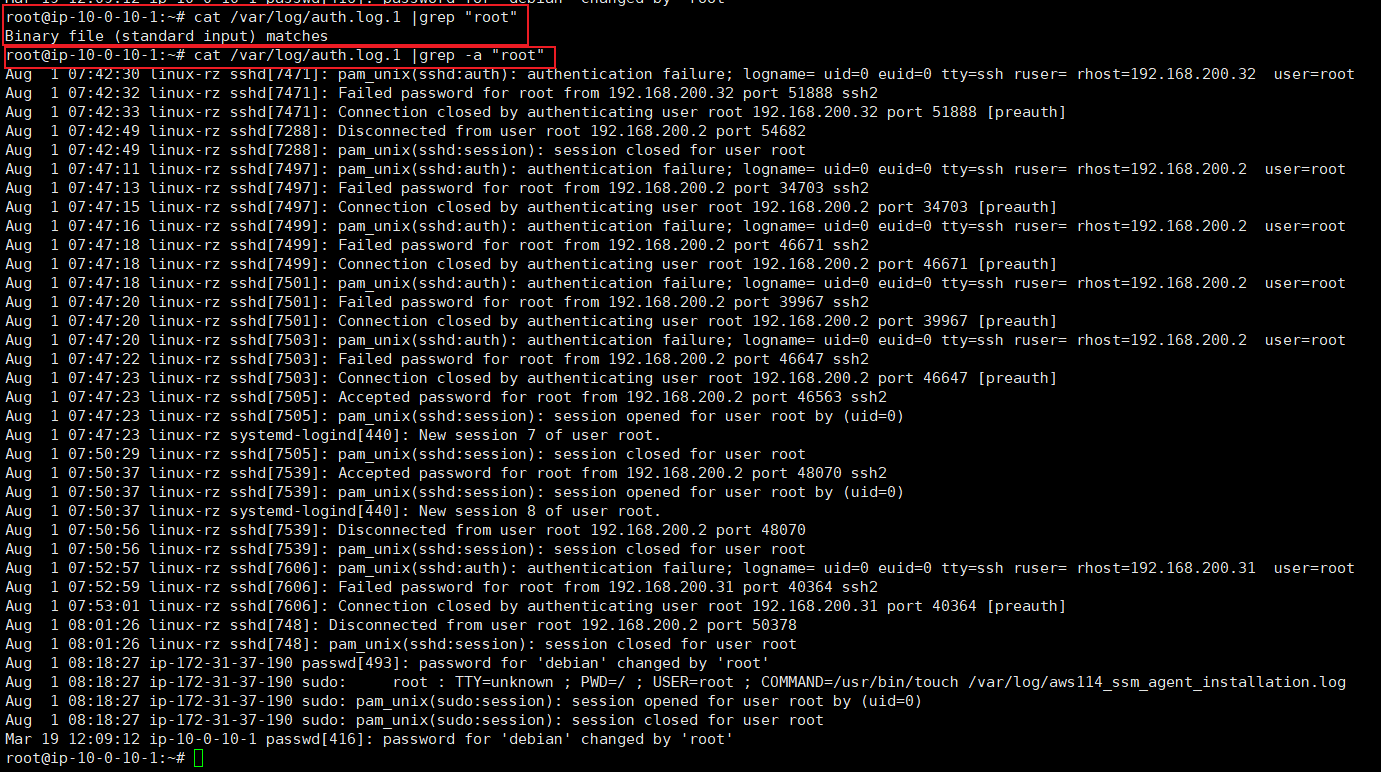
根据Failed password for root我们可以跟进过滤

1 | 可知有 192.168.200.32,192.168.200.2,192.168.200.31 |
2.ssh爆破成功登陆的IP是多少,如果有多个使用”,”分割
直接过滤 Accepted password

1 | flag{192.168.200.2} |
3.爆破用户名字典是什么?如果有多个使用”,”分割
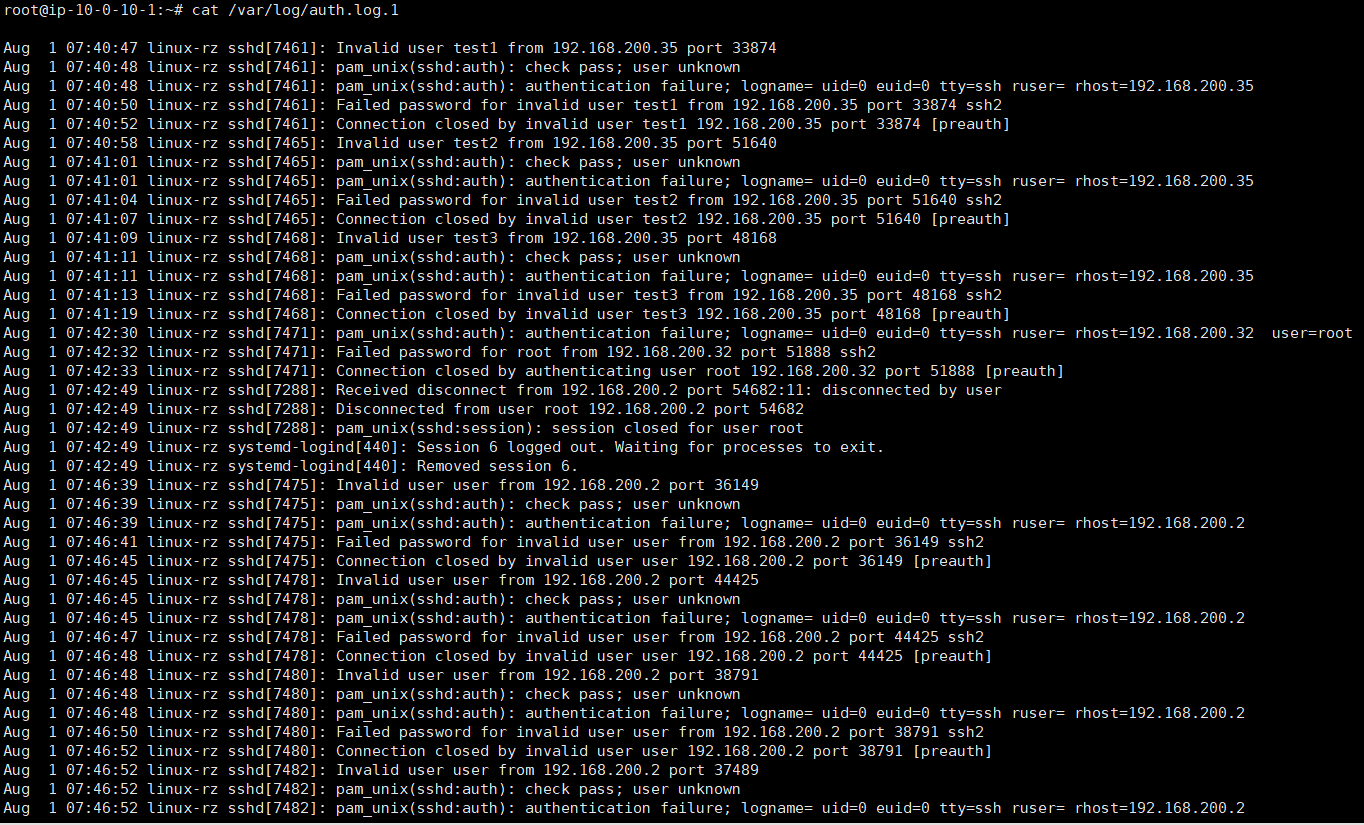
这里我的思考点是错的 一开始 想的爆破字典
就直接过滤了192.168.200.2
然后交了多次 然后全局看ssh日志文件
1 | flag{user,hello,root,test3,test2,test1} |
4.登陆成功的IP共爆破了多少次
- 查连接断开次数 Connection closed by authenticating

1 | flag{4} |
5.黑客登陆主机后新建了一个后门用户,用户名是多少
- 查看/etc/passwd
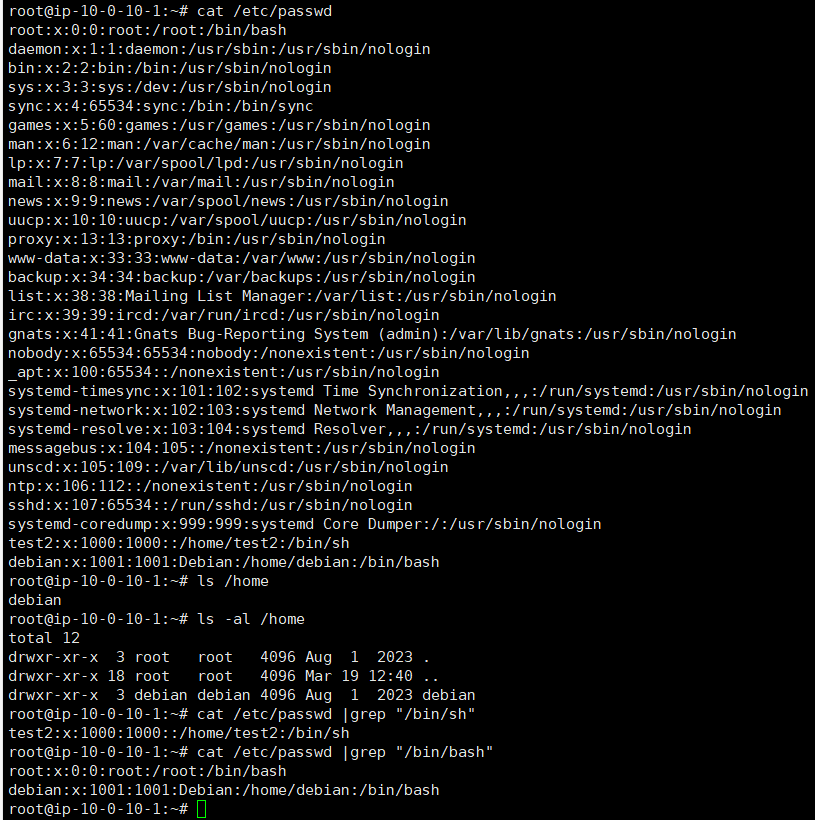
能进行登陆的就只有 root、debian、test2
1 | 最终确定 主机后新建了一个test2后门用户 |
- 直接查看auth.log 过滤 new user亦可

这题挺不错的 就是 美中不足的点是 flag的提交的顺序真的难受,
要按一定的顺序且是awk排的顺序
接下来就是跟着师傅使用awk、pwel环节
1.有多少IP在爆破主机ssh的root帐号,如果有多个使用”,”分割
cat /var/log/auth.log.1 | grep -a "Failed password for root" | awk '{print $11}' | sort | uniq -c | sort -nr | more

2.ssh爆破成功登陆的IP是多少,如果有多个使用”,”分割
cat /var/log/auth.log.1 | grep -a "Accepted " | awk '{print $11}' | sort | uniq -c | sort -nr | more

3.爆破用户名字典是什么?如果有多个使用”,”分割
cat /var/log/auth.log.1 | grep -a "Failed password" |perl -e 'while($_=<>){ /for(.*?) from/; print "$1\n";}'|uniq -c|sort -nr

4.登陆成功的IP共爆破了多少次
cat /var/log/auth.log.1 | grep -a "Failed password for root" | awk '{print $11}' | sort | uniq -c | sort -nr | more

解释
grep -a "Failed password for root" /var/log/auth.log.1
该部分使用 grep 命令在文件 /var/log/auth.log.1 中查找包含字符串 “Failed password for root” 的行
-a 选项表示以二进制模式处理文件,通常用于处理非文本文件
awk '{print $11}'
该部分使用 awk 命令从匹配到的行中提取出第11个字段,即IP地址
默认情况下,awk 以空格为字段分隔符,因此这里假设IP地址是在日志中的第11个字段
sort
该部分使用 sort 命令对提取出的IP地址进行排序。这是为了让相同的IP地址相邻,以便后面的统计。
uniq -c
该部分使用uniq -c命令进行唯一性和计数,它会显示每个唯一的IP地址及其出现的次数
-c 选项用于显示每行重复出现的次数。
sort -nr
该部分使用 sort -nr 命令对计数结果进行排序,其中 -n 表示按数字顺序排序,-r 表示逆序(从高到低)排序